
Apache Chukwa User Guide
This chapter is the detailed configuration guide to Apache Chukwa configuration.
Please read this chapter carefully and ensure that all requirements have been satisfied. Failure to do so will cause you (and us) grief debugging strange errors and/or data loss.
Apache Chukwa uses the same configuration system as Apache Hadoop. To configure a deploy, edit a file of environment variables in etc/chukwa/chukwa-env.sh -- this configuration is used mostly by the launcher shell scripts getting the cluster off the ground -- and then add configuration to an XML file to do things like override Apache Chukwa defaults, tell Apache Chukwa what Filesystem to use, or the location of the HBase configuration.
When running in distributed mode, after you make an edit to an Apache Chukwa configuration, make sure you copy the content of the conf directory to all nodes of the cluster. Apache Chukwa will not do this for you. Use rsync.
Pre-requisites
Apache Chukwa should work on any POSIX platform, but GNU/Linux is the only production platform that has been tested extensively. Apache Chukwa has also been used successfully on Mac OS X, which several members of Apache Chukwa team use for development.
The only absolute software requirements are Java 1.6 or better, Apache ZooKeeper 3.4.5, Apache HBase 1.2.0 and Apache Hadoop 2.7.2.
Apache Chukwa cluster management scripts rely on ssh; these scripts, however, are not required if you have some alternate mechanism for starting and stopping daemons.
Installing Apache Chukwa
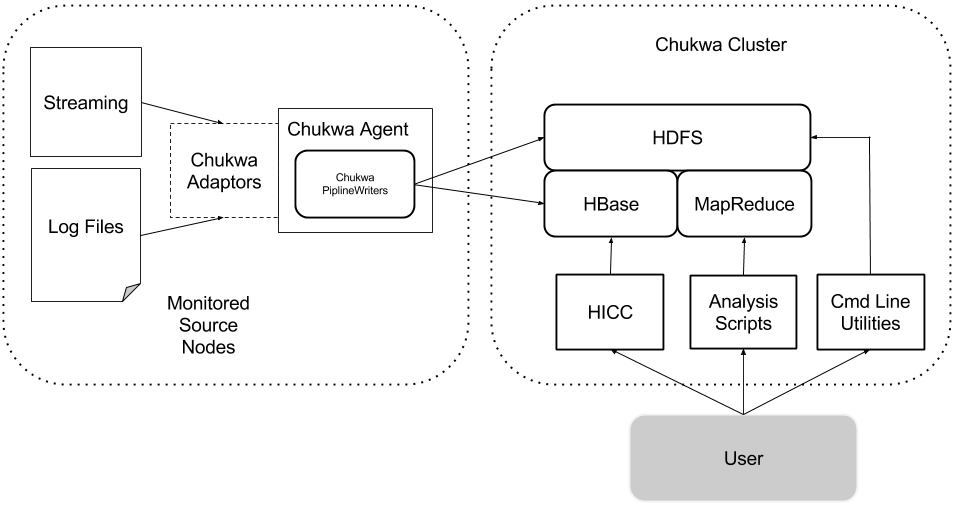
A minimal Apache Chukwa deployment has five components:
- A Apache Hadoop and Apache HBase cluster on which Apache Chukwa will process data (referred to as Apache Chukwa cluster).
- One or more agent processes, that send monitoring data to HBase. The nodes with active agent processes are referred to as the monitored source nodes.
- Data analytics script, summarize Apache Hadoop Cluster Health.
- HICC, Apache Chukwa visualization tool.
First Steps
- Obtain a copy of Apache Chukwa. You can find the latest release on the Apache Chukwa release page.
- Un-tar the release, via tar xzf.
- Make sure a copy of Apache Chukwa is available on each node being monitored.
- We refer to the directory containing Apache Chukwa as CHUKWA_HOME. It may be helpful to set CHUKWA_HOME explicitly in your environment, but Apache Chukwa does not require that you do so.
General Configuration
- Make sure that JAVA_HOME is set correctly and points to a Java 1.6 JRE. It's generally best to set this in CHUKWA_HOME/etc/chukwa/chukwa-env.sh.
- In CHUKWA_HOME/etc/chukwa/chukwa-env.sh, set CHUKWA_LOG_DIR and CHUKWA_PID_DIR to the directories where Apache Chukwa should store its console logs and pid files. The pid directory must not be shared between different Apache Chukwa instances: it should be local, not NFS-mounted.
- Optionally, set CHUKWA_IDENT_STRING. This string is used to name Apache Chukwa's own console log files.
Agents
Agents are the Apache Chukwa processes that actually produce data. This section describes how to configure and run them. More details are available in the Agent configuration guide.
Configuration
First, edit $CHUKWA_HOME/etc/chukwa/chukwa-env.sh In addition to the general directions given above, you should set HADOOP_CONF_DIR and HBASE_CONF_DIR. This should be Apache Hadoop deployment Apache Chukwa will use to store collected data. You will get a version mismatch error if this is configured incorrectly.
Edit the CHUKWA_HOME/etc/chukwa/initial_adaptors configuration file. This is where you tell Apache Chukwa what log files to monitor. See the adaptor configuration guide for a list of available adaptors.
There are a number of optional settings in $CHUKWA_HOME/etc/chukwa/chukwa-agent-conf.xml:
- The most important of these is the cluster/group name that identifies the monitored source nodes. This value is stored in each Chunk of collected data; you can therefore use it to distinguish data coming from different groups of machines.
<property> <name>chukwaAgent.tags</name> <value>cluster="demo"</value> <description>The cluster's name for this agent</description> </property> - Another important option is chukwaAgent.checkpoint.dir. This is the directory Apache Chukwa will use for its periodic checkpoints of running adaptors. It must not be a shared directory; use a local, not NFS-mount, directory.
- Setting the option chukwaAgent.control.remote will disallow remote connections to the agent control socket.
Use HBase For Data Storage
- Configuring the pipeline: set HBaseWriter as your writer, or add it to the pipeline if you are using
<property> <name>chukwa.agent.connector</name> <value>org.apache.hadoop.chukwa.datacollection.connector.PipelineConnector</value> </property> <property> <name>chukwa.pipeline</name> <value>org.apache.hadoop.chukwa.datacollection.writer.hbase.HBaseWriter</value> </property>
Use HDFS For Data Storage
The one mandatory configuration parameter is writer.hdfs.filesystem. This should be set to the HDFS root URL on which Apache Chukwa will store data. Various optional configuration options are described in the pipeline configuration guide.
Starting, Stopping, And Monitoring
To run an agent process on a single node, use:
sbin/chukwa-daemon.sh start agent
Typically, agents run as daemons. The script bin/start-agents.sh will ssh to each machine listed in etc/chukwa/agents and start an agent, running in the background. The script bin/stop-agents.sh does the reverse.
You can, of course, use any other daemon-management system you like. For instance, tools/init.d includes init scripts for running Apache Chukwa agents.
To check if an agent is working properly, you can telnet to the control port (9093 by default) and hit "enter". You will get a status message if the agent is running normally.
Configuring Apache Hadoop For Monitoring
One of the key goals for Apache Chukwa is to collect logs from Apache Hadoop clusters. This section describes how to configure Apache Hadoop to send its logs to Apache Chukwa. Note that these directions require Apache Hadoop 0.205.0+. Earlier versions of Apache Hadoop do not have the hooks that Apache Chukwa requires in order to grab MapReduce job logs.
Apache Hadoop configuration files are located in HADOOP_HOME/etc/hadoop. To setup Apache Chukwa to collect logs from Apache Hadoop, you need to change some of Apache Hadoop configuration files.
- Copy CHUKWA_HOME/etc/chukwa/hadoop-log4j.properties file to HADOOP_CONF_DIR/log4j.properties
- Copy CHUKWA_HOME/etc/chukwa/hadoop-metrics2.properties file to HADOOP_CONF_DIR/hadoop-metrics2.properties
- Edit HADOOP_HOME/etc/hadoop/hadoop-metrics2.properties file and change $CHUKWA_LOG_DIR to your actual CHUKWA log dirctory (ie, CHUKWA_HOME/var/log)
Setup HBase Table
Apache Chukwa is moving towards a model of using HBase to store metrics data to allow real-time charting. This section describes how to configure HBase and HICC to work together.
- Presently, we support HBase 0.96+. If you have older HBase jars anywhere, they will cause linkage errors. Check for and remove them.
- Setting up tables:
hbase/bin/hbase shell < etc/chukwa/hbase.schema
Troubleshooting Tips
UNIX Processes For Apache Chukwa Data Processes
Apache Chukwa Data Processors are identified by:
org.apache.hadoop.chukwa.datacollection.agent.ChukwaAgent org.apache.hadoop.chukwa.hicc.HiccWebServer
The processes are scheduled execution, therefore they are not always visible from the process list.
Emergency Shutdown Procedure
If the system is not functioning properly and you cannot find an answer in the Administration Guide, execute the kill command. The current state of the java process will be written to the log files. You can analyze these files to determine the cause of the problem.
kill -3 <pid>