
Purpose
Chukwa is a system for large-scale reliable log collection and processing with Hadoop. The Chukwa design overview discusses the overall architecture of Chukwa. You should read that document before this one. The purpose of this document is to help you install and configure Chukwa.
Pre-requisites
Chukwa should work on any POSIX platform, but GNU/Linux is the only production platform that has been tested extensively. Chukwa has also been used successfully on Mac OS X, which several members of the Chukwa team use for development.
Software requirements are Java 1.6 or better, ZooKeeper 3.4.5, HBase 1.0.0 and Hadoop 2.6.0.
The Chukwa cluster management scripts rely on ssh; these scripts, however, are not required if you have some alternate mechanism for starting and stopping daemons.
Installing Chukwa
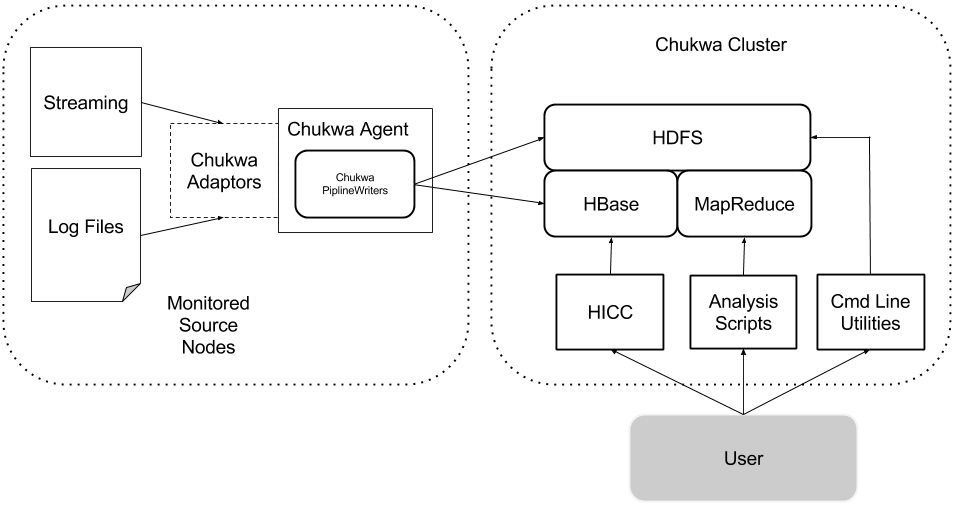
A minimal Chukwa deployment has five components:
- A Hadoop and HBase cluster on which Chukwa will process data (referred to as the Chukwa cluster).
- One or more agent processes, that send monitoring data to HBase. The nodes with active agent processes are referred to as the monitored source nodes.
- Solr Cloud cluster which Chukwa will store indexed log files.
- Data analytics script, summarize Hadoop Cluster Health.
- HICC, the Chukwa visualization tool.
First Steps
- Obtain a copy of Chukwa. You can find the latest release on the Chukwa release page (or alternatively check the source code out from SCM).
- Un-tar the release, via tar xzf.
- Make sure a copy of Chukwa is available on each node being monitored.
- We refer to the directory containing Chukwa as CHUKWA_HOME. It may be useful to set CHUKWA_HOME explicitly in your environment for ease of use.
Setting Up Chukwa Cluster
Configure Hadoop and HBase
- Copy Chukwa files to Hadoop and HBase directories:
cp $CHUKWA_HOME/etc/chukwa/hadoop-log4j.properties $HADOOP_CONF_DIR/log4j.properties cp $CHUKWA_HOME/etc/chukwa/hadoop-metrics2.properties $HADOOP_CONF_DIR/hadoop-metrics2.properties cp $CHUKWA_HOME/share/chukwa/chukwa-0.7.0-client.jar $HADOOP_HOME/share/hadoop/common/lib cp $CHUKWA_HOME/share/chukwa/lib/json-simple-1.1.jar $HADOOP_HOME/share/hadoop/common/lib cp $CHUKWA_HOME/etc/chukwa/hbase-log4j.properties $HBASE_CONF_DIR/log4j.properties cp $CHUKWA_HOME/etc/chukwa/hadoop-metrics2-hbase.properties $HBASE_CONF_DIR/hadoop-metrics2-hbase.properties cp $CHUKWA_HOME/share/chukwa/chukwa-0.7.0-client.jar $HBASE_HOME/lib cp $CHUKWA_HOME/share/chukwa/lib/json-simple-1.1.jar $HBASE_HOME/lib
- Restart your Hadoop Cluster. General Hadoop configuration is available at: Hadoop Configuration. N.B. You may see some additional logging messages at this stage which looks as if error(s) are present. These messages are showing up because the log4j socket appender writes to stderr for warn messages when it is unable to stream logs to a log4j socket server. If the Chukwa agent is started with socket adaptors prior to Hadoop and HBase, those messages will not show up. For the time being do not worry about these messages, they will disappear once Chukwa agent is started with socket adaptors.
- Make sure HBase is started. General HBASE configuration is available at: HBase Configuration
- After Hadoop and HBase are started, run:
bin/hbase shell < $CHUKWA_HOME/etc/chukwa/hbase.schema
This procedure initializes the default Chukwa HBase schema.
Configuring And Starting Chukwa Agent
- Edit CHUKWA_HOME/etc/chukwa/chukwa-env.sh. Make sure that JAVA_HOME, HADOOP_CONF_DIR, and HBASE_CONF_DIR are set correctly.
- Edit CHUKWA_HOME/etc/chukwa/chukwa-agent-conf.xml. Make sure that solr.cloud.address are set correctly.
- In CHUKWA_HOME, run:
sbin/chukwa-daemon.sh start agent
Setup Solr to index Service log files
- Start Solr with Chukwa Solr configuration:
java -Dbootstrap_confdir=$CHUKWA_HOME/etc/solr/logs/conf -Dcollection.configName=myconf -Djetty.port=7574 -DzkHost=localhost:2181 -jar start
Setup Cluster Aggregation Script
For data analytics with Apache Pig, there are some additional environment setup. Apache Pig does not use the same environment variable name as Hadoop, therefore make sure the following environment are setup correctly:
- Download and setup Apache Pig 0.9.1.
- Define Apache Pig class path:
export PIG_CLASSPATH=$HADOOP_CONF_DIR:$HBASE_CONF_DIR
- Create a jar file of HBASE_CONF_DIR, run:
jar cf $CHUKWA_HOME/hbase-env.jar $HBASE_CONF_DIR
- Setup a cron job or Hudson job for analytics script to run periodically:
pig -Dpig.additional.jars=${HBASE_HOME}/hbase-1.0.0.jar:${HBASE_HOME}/lib/zookeeper-3.4.5.jar:${PIG_PATH}/pig.jar:${CHUKWA_HOME}/hbase-env.jar ${CHUKWA_HOME}/script/pig/ClusterSummary.pig