
Introduction
Chukwa aims to provide a flexible and powerful platform for distributed data collection and rapid data processing. Our goal is to produce a system that's usable today, but that can be modified to take advantage of newer storage technologies (HDFS appends, HBase, etc) as they mature. In order to maintain this flexibility, Chukwa is structured as a pipeline of collection and processing stages, with clean and narrow interfaces between stages. This will facilitate future innovation without breaking existing code.
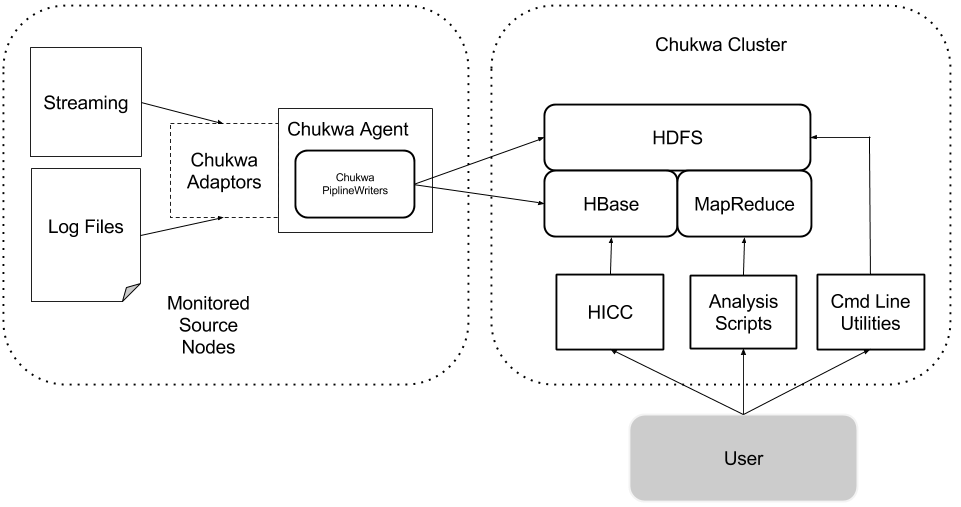
Chukwa has five primary components:
- Adaptors that collect data from various data source.
- Agents that run on each machine and emit data.
- ETL Processes for parsing and archiving the data.
- Data Analytics Scripts for aggregate Hadoop cluster health.
- HICC, the Hadoop Infrastructure Care Center; a web-portal style interface for displaying data.
Below is a figure showing the Chukwa data pipeline, annotated with data dwell times at each stage. A more detailed figure is available at the end of this document.
Agents and Adaptors
Chukwa agents do not collect some particular fixed set of data. Rather, they support dynamically starting and stopping Adaptors, which small dynamically-controllable modules that run inside the Agent process and are responsible for the actual collection of data.
These dynamically controllable data sources are called adaptors, since they generally are wrapping some other data source, such as a file or a Unix command-line tool. The Chukwa agent guide includes an up-to-date list of available Adaptors.
Data sources need to be dynamically controllable because the particular data being collected from a machine changes over time, and varies from machine to machine. For example, as Hadoop tasks start and stop, different log files must be monitored. We might want to increase our collection rate if we detect anomalies. And of course, it makes no sense to collect Hadoop metrics on an NFS server.
Data Model
Chukwa Adaptors emit data in Chunks. A Chunk is a sequence of bytes, with some metadata. Several of these are set automatically by the Agent or Adaptors. Two of them require user intervention: cluster name and datatype. Cluster name is specified in conf/chukwa-agent-conf.xml, and is global to each Agent process. Datatype describes the expected format of the data collected by an Adaptor instance, and it is specified when that instance is started.
The following table lists the Chunk metadata fields.
| Field | Meaning | Source |
| Source | Hostname where Chunk was generated | Automatic |
| Cluster | Cluster host is associated with | Specified by user in agent config |
| Datatype | Format of output | Specified by user when Adaptor started |
| Sequence ID | Offset of Chunk in stream | Automatic, initial offset specified when Adaptor started |
| Name | Name of data source | Automatic, chosen by Adaptor |
Conceptually, each Adaptor emits a semi-infinite stream of bytes, numbered starting from zero. The sequence ID specifies how many bytes each Adaptor has sent, including the current chunk. So if an adaptor emits a chunk containing the first 100 bytes from a file, the sequenceID of that Chunk will be 100. And the second hundred bytes will have sequence ID 200. This may seem a little peculiar, but it's actually the same way that TCP sequence numbers work.
Adaptors need to take sequence ID as a parameter so that they can resume correctly after a crash, and not send redundant data. When starting adaptors, it's usually save to specify 0 as an ID, but it's sometimes useful to specify something else. For instance, it lets you do things like only tail the second half of a file.
ETL Processes
Chukwa Agents can write data directly to HBase or sequence files. This is convenient for rapidly getting data committed to stable storage.
HBase provides index by primary key, and manage data compaction. It is better for continous monitoring of data stream, and periodically produce reports.
HDFS provides better throughput for working with large volume of data. It is more suitable for one time research analysis job . But it's less convenient for finding particular data items. As a result, Chukwa has a toolbox of MapReduce jobs for organizing and processing incoming data.
These jobs come in two kinds: Archiving and Demux. The archiving jobs simply take Chunks from their input, and output new sequence files of Chunks, ordered and grouped. They do no parsing or modification of the contents. (There are several different archiving jobs, that differ in precisely how they group the data.)
Demux, in contrast, take Chunks as input and parse them to produce ChukwaRecords, which are sets of key-value pairs. Demux can run as a MapReduce job or as part of HBaseWriter.
For details on controlling this part of the pipeline, see the Pipeline guide. For details about the file formats, and how to use the collected data, see the Programming guide.
Data Analytics Scripts
Data stored in HBase are aggregated by data analytic scripts to provide visualization and interpretation of health of Hadoop cluster. Data analytics scripts are written in PigLatin, the high level language provides easy to understand programming examples for data analyst to create additional scripts to visualize data on HICC.
HICC
HICC, the Hadoop Infrastructure Care Center is a web-portal style interface for displaying data. Data is fetched from HBase, which in turn is populated by collector or data analytic scripts that runs on the collected data, after Demux. The Administration guide has details on setting up HICC.
Collectors (Deprecated)
The origin design of collector is to reduce the number of TCP connections for collecting data from various source, provide high availability and wire compatibility across versions. Data transfer reliability has been improved in HDFS client and HBase client. The original problem that Chukwa Collector tried to solve is no longer high priority in Chukwa data collection framework because both HDFS and HBase are in better position in solving data transport and replication problem. Hence, datanode and HBase Region servers are replacement for Chukwa collectors.
Chukwa has adopted to use HBase to ensure data arrival in milli-seconds and also make data available to down steam application at the same time. This will enable monitoring application to have near realtime view as soon as data are arriving in the system. The file rolling, archiving are replaced by HBase Region Server minor and major compactions.